近日,信息学院沈思淇老师课题组和国防科技大学计算机学院师生合作,在国际人工智能顶级会议neurips 2022上以“resq: a residual q function-based approach for multi-agent reinforcement learning value factorization”为题发表了一篇关于多智能体强化学习研究成果的论文。该论文是信息学院首篇neurips会议的spotlight论文,neurips 2022的spotlight论文接收率约为5%。

多智能体强化学习难以训练,可扩展性差,学术界和工业界的主流解决方法是采用价值分解算法来训练多智能体,但现有主流价值分解方法存在表达能力不足,学习效率较低等问题。针对这些问题,该论文提出了resq(基于残差q函数的价值分解方法),通过遮挡部分状态动作对的方式,将多智能体价值函数分解为主价值函数和残差价值函数的和。主价值函数用于重构与原有价值函数相同的最优策略,而残差价值函数用于保存被遮挡的状态动作对的价值。论文在矩阵游戏、星际争霸、捕食者游戏中进行了充分实验,证明resq方法的有效性。
该论文第一作者是信息学院沈思淇老师,通讯作者是国防科技大学符永铨老师,信息学院计算机科学与技术系2021级硕士生邱梦薇、2020级硕士生刘俊分别为学生一作和学生二作,其他作者还有厦大刘伟权博士,王程老师,国防科技大学刘新旺老师。
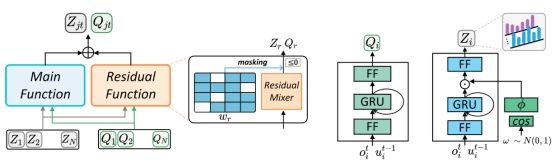
resq方法框架图
neurips(全称 neural information processing systems)是人工智能、机器学习、计算神经科学领域的顶级学术会议。今年是第36届会议,大会讨论的内容包含深度学习、强化学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多细分领域。neurips 2022共有 10411 篇论文投稿,接收率为 25.6%。
论文链接:https://openreview.net/forum?id=bdnz_1qhlcw