近日,信息学院李辉、纪荣嵘老师和腾讯工蜂合作,在acm sigsoft international symposium on software testing and analysis (issta 2023) 上以“refbert: a two-stage pre-trained framework for automatic rename refactoring”为题发表了一篇利用大模型实现代码变量名自动重构的论文。该成果是厦门大学信息学院首次以第一单位在issta会议上发表的论文,受科技创新2030—“新一代人工智能”重大项目“紧致化多模态大模型构建关键技术研究”及2021年ccf-腾讯犀牛鸟基金“基于预训练方法的代码搜索技术研究”支持。
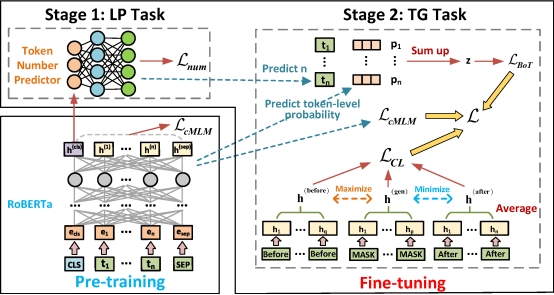
重构是软件进化中提高源代码质量和可维护性的一种必不可少的实践。代码变量名重构是最常执行的重构类型,但目前尚缺少自动化实现代码变量名重构的研究。本论文提出了一种两阶段的自动代码变量名重构框架。本论文指出代码变量名重构与各种流行的学习范式之间的联系,以及其与自然语言处理的文本生成任务之间的区别。本论文将代码变量名重构任务分为预测sub-token长度和生成变量名两个子任务,并引入约束掩蔽语言建模、对比学习和bag-of-tokens损失,结合大模型实现自动代码变量名重构。本论文在收集的重构数据集上进行了大量实验,结果表明re2bert可以在变量名重构任务中生成更准确、更有意义的变量名。
该论文第一作者是信息学院计算机科学与技术系2021级硕士生刘好,在信息学院李辉副教授(通讯作者)和纪荣嵘教授、腾讯工蜂合作者共同指导下完成。
论文链接:
图文:刘好/投稿:李辉